
Data centers are spending over $450 billion on AI infrastructure in 2026, with H100 and B200 GPU clusters representing the largest share of this investment. Companies seeking to deploy 100 to 10,000 GPUs face upfront costs ranging from $5 million to over $500 million, creating a significant financing challenge.
To address this, organizations are leveraging three primary funding approaches: traditional capital expenditure, cloud rental models, and asset-backed financing. This article details how these models are enabling rapid H100 and B200 deployments despite unprecedented capital requirements.
The growing race for AI compute in 2026
Data centers are funding H100 and B200 GPU deployments through three primary methods: direct capital expenditure from their own cash reserves, asset-backed debt financing where the GPUs themselves serve as collateral, and strategic partnerships where chip manufacturers co-invest in infrastructure buildout. The fastest-growing approach is asset-backed financing because it allows companies to deploy thousands of GPUs in weeks rather than months while preserving equity and limiting liability to the pledged hardware alone.
The numbers tell the story. NVIDIA's data center revenue hit $35.6 billion in just the first quarter of 2025, capturing roughly 90% of all AI accelerator spending globally. Companies that secure GPU capacity first gain deployment advantages measured in weeks, not quarters—which is why financing speed has become as critical as financing cost.
Consider OpenAI's infrastructure roadmap through 2030, which requires $207 billion in capital. Lambda raised $1.5 billion specifically to purchase GPUs and build out data center capacity. Even mid-sized AI companies face $5 million to $50 million in upfront costs for initial deployments. Traditional bank loans take 60 to 90 days for approval—a timeline that misses entire product cycles in AI development.
Most organizations can't write nine-figure checks upfront, and venture capital firms want equity spent on product development rather than hardware purchases. This gap between demand and available capital created the market for GPU-specific financing products that close in days instead of months.
Understanding H100 and B200 costs and availability
The H100 is NVIDIA's current-generation data center GPU designed for AI training and inference, while the B200 represents the next-generation Blackwell architecture with roughly 2.5 times the performance per watt. A single H100 GPU costs between $25,000 and $40,000 depending on the variant, while early B200 pricing ranges from $30,000 to $70,000 due to limited availability.
An 8-GPU H100 server—the standard building block for AI infrastructure—runs $200,000 to $320,000 fully configured. Scale that to 1,000 GPUs for a mid-sized deployment and you're looking at $25 million to $40 million in hardware costs alone, before accounting for networking, cooling, or power infrastructure.
Two H100 variants dominate the market. The H100 SXM offers higher performance through specialized high-bandwidth interconnects but requires custom server designs. The H100 PCIe fits standard servers and provides more deployment flexibility at slightly lower performance. Data centers choose SXM for large-scale training clusters where maximum performance matters, and PCIe for inference workloads or mixed-use environments.
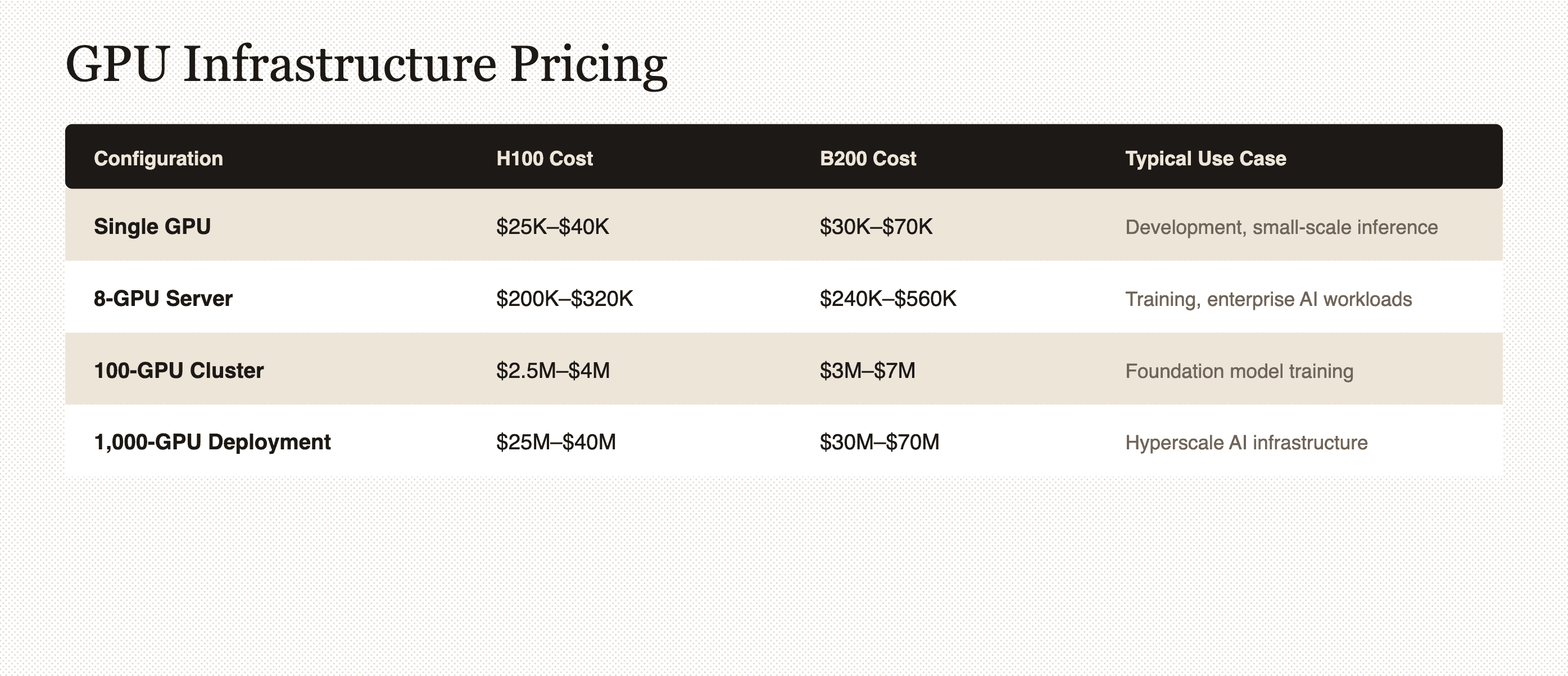
Price ranges across major suppliers
Pricing varies by 20% to 40% depending on where you buy. Direct purchases from NVIDIA offer the best allocation priority but require enterprise relationships and minimum order volumes that exclude smaller buyers. Authorized distributors add 10% to 15% markup over NVIDIA's direct pricing but accept smaller orders and provide faster delivery for available inventory.
The secondary market commands premium pricing—often 20% to 40% above manufacturer suggested retail price—during shortage periods, though it offers immediate availability when direct channels show three-month lead times. OEM server vendors like Dell, HPE, and Supermicro bundle GPUs into complete systems with support contracts, which simplifies procurement but typically costs 15% to 25% more than buying components separately.
B200 availability remains the primary constraint in 2026. Most supply is allocated to hyperscalers who placed orders in 2024 and early 2025, leaving new buyers facing 12 to 18-month wait times for volume orders.
Procurement timelines and lead times
H100 orders placed directly with NVIDIA or tier-one OEMs typically deliver in two to three months for standard configurations. Distribution channels offer two to eight-week delivery for in-stock inventory, with longer timelines for large clustered orders requiring custom networking and validation.
B200 procurement works differently. Orders placed in late 2025 or 2026 face 12 to 18-month lead times, and the chip is effectively sold out through mid-2026 for buyers who didn't secure allocation early. The secondary market offers faster access—days to weeks for modest quantities—but at significant price premiums that can add $10,000 to $20,000 per GPU.
A company that needs 500 GPUs operational in 60 days can't wait for six-month procurement cycles, which drives them toward secondary market purchases at premium prices or cloud rental models. Financing structures that close in seven to 30 days match the urgency of AI deployment timelines rather than forcing companies to align their product roadmaps with traditional banking schedules.
Power and infrastructure constraints affecting deployments
Power availability has become the primary bottleneck for GPU deployments, surpassing even chip supply as the limiting factor. Data centers consumed 415 terawatt-hours globally in 2024—up 73% from 240 terawatt-hours in 2023. Grid connection wait times now stretch two to 10 years in constrained markets, with active moratoriums in Dublin, Amsterdam, and other major data center hubs.
A single H100 GPU draws 350 to 700 watts depending on configuration and workload, which means an 8-GPU server requires five to 10 kilowatts including cooling and networking overhead. Scale that to 1,000 GPUs and you need five to 10 megawatts of continuous power—equivalent to a small industrial facility.
The infrastructure costs extend far beyond the electric bill:
- Power infrastructure: $10 million to $50 million per data center site for substation connections and distribution equipment
- Liquid cooling systems: $5 million to $20 million for dense GPU deployments
- High-speed networking: $2 million to $10 million for InfiniBand or RoCE GPU clusters
- Purpose-built facilities: $50 million to $200 million in real estate and construction
The total infrastructure cost typically runs two to three times the GPU hardware cost. Traditional GPU financing covers only the chips themselves, leaving data centers to fund power, cooling, and networking separately. Markets like Texas and the Middle East offer abundant power capacity, while Northern Virginia and London face severe constraints—a dynamic that's driving data center operators to secure power commitments before financing GPU purchases.
Financing structures for large-scale GPU projects
Three primary financing approaches dominate the market, each serving different buyer profiles based on scale, timeline requirements, and capital availability.
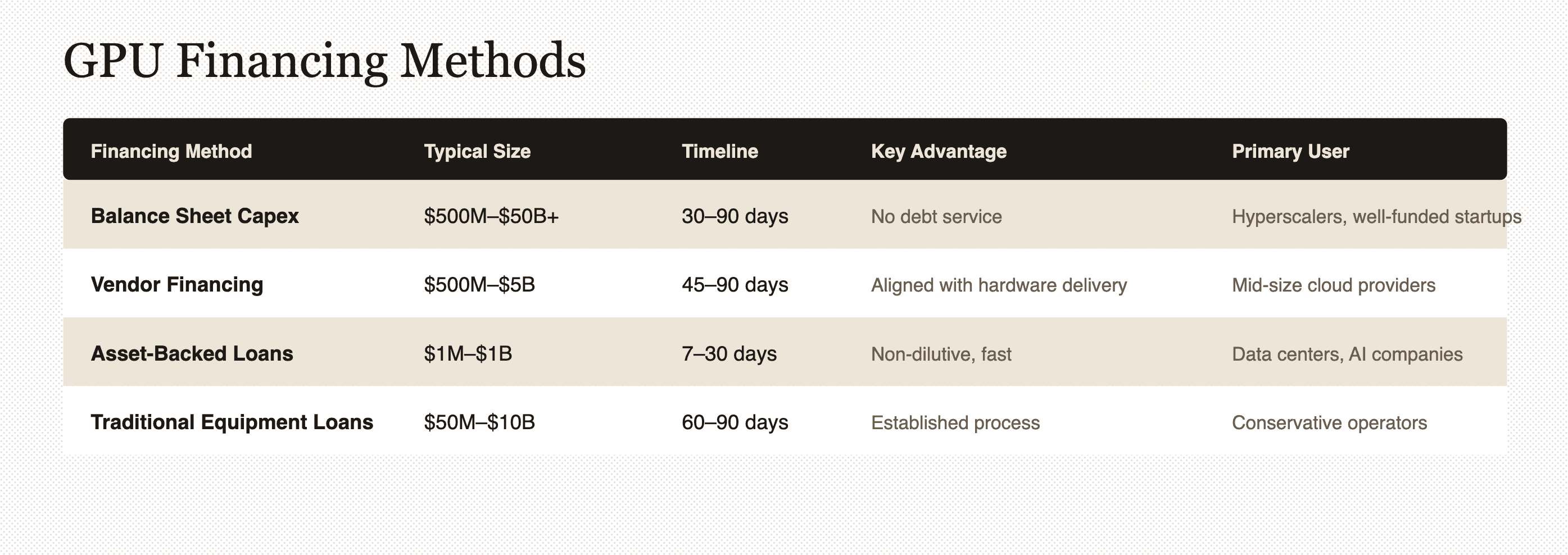
Balance sheet capex is how hyperscalers like AWS, Google, and Microsoft fund deployments—they write checks directly from cash reserves or equity raises. The advantage is complete ownership and control; the disadvantage is that it requires massive capital reserves that most companies don't have.
Vendor and strategic financing involves GPU manufacturers or strategic partners providing capital to accelerate deployments. NVIDIA's $2 billion investment in CoreWeave exemplifies this model—the chip maker co-funds infrastructure buildout to secure long-term demand for its products.
Traditional equipment financing through banks and specialized lenders follows established processes but typically requires 60 to 90 days for approval and minimum deal sizes of $50 million or more. Banks offer conservative loan-to-value ratios of 40% to 50% because they're applying conventional equipment lending frameworks to a rapidly evolving asset class they don't fully understand.
Asset-backed loans and SPVs
Asset-backed GPU financing structures the loan around the collateral itself rather than the borrower's credit history or balance sheet. The borrower creates a Special Purpose Vehicle (SPV)—a bankruptcy-remote legal entity that exists solely to hold the GPU collateral and isolate it from the borrower's other business risks.
Here's how the process works. First, the borrower identifies the specific GPU hardware to be financed—model, quantity, and data center location. The borrower then establishes an SPV with an independent manager that takes legal ownership of the GPUs. The borrower provides 20% to 30% equity as a down payment, which the SPV uses to purchase the hardware from NVIDIA or OEM suppliers.
Once the GPUs are delivered, installed, and operational at the data center, the lender advances 60% to 70% loan-to-value against the collateral. The borrower maintains full operational use of the GPUs—they remain deployed and generating revenue while securing the loan. The loan is serviced from GPU revenue like compute sales, inference services, or training contracts.
The advantages of this structure include:
- Non-recourse liability: The borrower's exposure is limited to the pledged collateral
- Bankruptcy protection: The SPV isolates GPU assets from other business risks
- Operational continuity: GPUs stay deployed and revenue-generating
- Faster approval: Seven to 30 days versus 60 to 90 days for traditional loans
Typical terms offer 60% to 70% loan-to-value for H100 and B200 enterprise GPUs, 12 to 36-month loan periods, and deal sizes from $5 million to $100 million or more per transaction.
Non-recourse vs recourse options
Non-recourse loans limit the lender's recovery solely to the pledged collateral—if the GPUs depreciate or the borrower defaults, the lender takes the hardware but cannot pursue other borrower assets or require personal guarantees. Recourse loans allow lenders to pursue the borrower's other assets or require corporate guarantees if the collateral proves insufficient to repay the debt.
Most AI startups and growth-stage companies are pre-profitable or have limited credit history, which makes traditional recourse loans difficult to obtain. Banks want personal guarantees or corporate guarantees that founders are unwilling or unable to provide. Non-recourse structures evaluate the collateral—GPU market value, depreciation trajectory, and revenue potential—rather than the borrower's balance sheet.
The trade-off is cost: non-recourse loans typically carry 2% to 3% higher interest rates because lenders assume more risk. However, this premium is acceptable for borrowers who value the limited liability protection and want to preserve their balance sheets for growth investments rather than hardware guarantees.
Rent vs buy vs finance TCO analysis
Total cost of ownership (TCO) measures the complete cost of acquiring and operating GPUs over a defined period, including hardware, infrastructure, operations, and opportunity costs. Three models dominate: cloud rental (pay hourly for GPU access), direct purchase (buy outright from capital reserves), and asset-backed financing (borrow 70% to 80% of GPU value).
Cloud rental requires zero upfront capital and includes full operational management by the provider, with typical costs of $2 to $5 per H100 GPU-hour. Direct purchase means paying $25,000 to $40,000 per H100 upfront plus infrastructure and operational costs, but you own the hardware outright. Asset-backed financing requires 20% to 30% down payment with the remainder borrowed, resulting in monthly debt service plus operational costs while retaining ownership.

The calculations assume 50% utilization for cloud rental—actual costs vary dramatically based on usage patterns.
Short-term vs long-term workloads
Workload duration and predictability determine the optimal approach. Short-term workloads under six months favor cloud rental because upfront capital costs and financing overhead don't justify brief deployment periods. A startup training a foundation model over three months would rent 500 H100s rather than purchase or finance them.
Medium-term workloads spanning six to 18 months create a decision point between asset-backed financing and cloud rental, depending on capital availability. Financing breaks even with cloud around eight to 12 months of usage, and ownership provides optionality for extended deployments.
Long-term workloads exceeding 18 months strongly favor direct purchase or financing. Ownership becomes significantly cheaper than rental after 18 to 24 months, making it the clear choice for data centers with multi-year customer contracts.
Factors influencing total cost
Several non-obvious costs affect TCO calculations beyond headline GPU prices. Cloud providers charge three to five times the amortized hardware cost to cover their margins, operations, and the flexibility premium. Data egress fees for moving training data or model outputs out of cloud environments can add 10% to 20% to total cloud costs.
On the ownership side, GPUs depreciate 30% to 50% annually, meaning owned hardware loses value while cloud providers absorb this risk. Managing GPU infrastructure requires specialized talent at $150,000 to $300,000 per infrastructure engineer. Hardware failures require replacement parts and downtime that cloud providers handle transparently.
Financing adds its own costs. Interest expense typically runs 8% to 15% annually, increasing the effective GPU cost. Down payment requirements of 30% to 40% tie up capital that could be deployed elsewhere. Some lenders charge 0.5% to 1% annually for collateral monitoring and custody services.
Key risks and ROI considerations
GPU investment returns come from four sources: direct compute revenue (selling GPU-hours at $2 to $5 per H100-hour market rates), product velocity (faster model training enables quicker launches), cost avoidance (owned or financed GPUs cost 60% to 80% less than cloud over 24+ months), and strategic optionality (owned infrastructure provides deployment flexibility).
A concrete example illustrates the math. A data center finances 500 H100 GPUs for $10 million at 70% loan-to-value on $15 million hardware value, resulting in $350,000 monthly debt service. Selling GPU compute at $3 per hour with 60% utilization generates $650,000 monthly revenue, yielding $300,000 monthly profit after debt service. The payback period is 15 months.
However, this assumes stable demand and utilization, which introduces execution risk.
Depreciation curves for H100 and B200
GPU depreciation—the decline in market value over time due to technological advancement and newer generation releases—directly impacts collateral value and resale potential. H100 GPUs depreciate 20% to 30% in year one as newer generations are announced, 15% to 25% in year two as B200 and B300 reach volume production, and 20% to 30% in year three as next-generation adoption accelerates.
Performance improvements drive this depreciation—each GPU generation delivers two to three times performance per dollar, making previous generations less competitive. Software optimizations increasingly target new architectures, reducing older GPU efficiency. Power efficiency improvements in newer chips reduce operational costs, increasing their relative value.
Lenders structure GPU loans with depreciation in mind, often requiring declining loan-to-value ratios over the loan term to maintain adequate collateral coverage. A 70% loan-to-value on day one might require collateral top-ups or principal paydowns if GPU values decline faster than expected.
Buyers can mitigate this risk by planning 24 to 36-month deployments—depreciation makes GPU investments uneconomical for periods shorter than 18 months, where cloud rental proves more efficient.
Macro volatility and usage forecasts
GPU financing depends on accurate usage and revenue forecasts, which carry business execution risk. Customer contract risk means enterprise GPU compute sales depend on signed agreements—forecast errors leave GPUs underutilized and unable to service debt. Market competition in GPU cloud pricing is intense, with new entrants or hyperscaler discounting compressing margins.
Supply-side risks include power availability (secured GPUs are worthless without capacity to run them), regulatory constraints (data center moratoriums can delay or prevent deployments), talent shortages (specialized skills command premium salaries), and vendor concentration (90% dependence on NVIDIA creates supply chain exposure).
Risk mitigation strategies include:
- Secure customer contracts before financing to de-risk revenue forecasts
- Match loan terms to contract duration (24-month customer contracts pair with 24-month financing)
- Maintain six to 12 months of debt service in cash reserves to weather demand volatility
- Diversify revenue across training, inference, and spot markets to reduce customer concentration risk
- Use fixed-rate financing to eliminate interest rate volatility
GPU financing is asset-backed debt, not speculative venture investment—lenders and borrowers both benefit from conservative utilization assumptions of 50% to 60% and stress-testing for 20% to 30% demand shortfalls.
Unlocking GPU deployments through smart financing
GPU financing has evolved from niche equipment lending to a strategic enabler of AI infrastructure deployment. Data centers and AI companies face $5 million to $500 million capital requirements that most organizations cannot or would prefer not to fund entirely from balance sheets.
Asset-backed financing provides 70% to 80% loan-to-value, seven to 30-day funding timelines, and non-recourse structures that preserve equity and limit liability. TCO analysis consistently shows that ownership through purchase or financing becomes economical after 12 to 18 months compared to cloud rental. Key risks include GPU depreciation of 50% to 70% over three years, demand volatility, and power or infrastructure constraints.
The decision framework is straightforward. Use cloud rental for workloads under 12 months, unpredictable demand, or limited capital situations. Choose direct purchase for long-term deployments exceeding 24 months when you have a strong balance sheet. Select asset-backed financing for medium-term deployments spanning 12 to 36 months, especially for growth-stage companies prioritizing capital preservation.
Traditional lenders still take 60 to 90 days for approvals and often don't understand GPU economics or depreciation curves. Cloud providers lock customers into rental models that become expensive over extended periods. The companies winning AI infrastructure deployments secure fast, flexible, non-dilutive financing aligned with AI deployment timelines.
Finance your next GPU deployment with GPULoans.com—get a financing quote in 48 hours for H100 and B200 clusters from $5 million to $100 million or more.
Frequently asked questions about AI GPU financing
What happens to financed GPUs if the borrower defaults on the loan?
In a non-recourse asset-backed structure, the lender takes possession of the GPU collateral held in the SPV and liquidates it through resale markets or redeployment to recover the outstanding loan balance; the borrower has no additional liability beyond the pledged hardware.
Can data centers finance GPUs that are already deployed and generating revenue?
Yes, many asset-backed lenders provide refinancing or cash-out loans against existing GPU infrastructure, allowing data centers to unlock capital from already-deployed hardware while maintaining operational use of the equipment.
Do GPU financing terms cover infrastructure costs like networking and cooling systems?
Most GPU-specific financing covers only the GPU hardware and servers; however, some lenders offer integrated infrastructure financing that includes high-speed networking, liquid cooling systems, and power infrastructure as part of a comprehensive data center buildout package.
How do lenders determine loan-to-value ratios for new GPU models like the B200?
Lenders evaluate loan-to-value based on manufacturer pricing, secondary market data, expected depreciation curves, and resale liquidity; newer models like the B200 typically receive 60% to 65% loan-to-value compared to 65% to 70% for established models like the H100 due to less pricing history and higher uncertainty.
What minimum GPU quantity or deal size do asset-backed lenders typically require?
Most institutional GPU lenders have minimum deal sizes of $5 million to $10 million (approximately 125 to 250 H100 GPUs) because the legal costs of establishing SPV structures and custody arrangements make smaller transactions uneconomical.
Are GPU financing interest rates fixed or variable throughout the loan term?
Both structures exist—fixed-rate loans provide payment predictability but typically carry 1% to 2% higher rates, while variable-rate loans tied to SOFR or other benchmarks offer lower initial rates but expose borrowers to interest rate risk over the loan term.